


这 Gemini 2.5 Flash 速度更快,价格更是无情碾压,甚至还有自动省钱模式,堪称“性价比卷王”。
榜二性能,榜外价格
在大模型竞技场(LMArena)里,Gemini 2.5 Flash以1392 ELO高分和GPT-4.5、Grok 3并列第二,仅次于自家大哥Gemini 2.5 Pro。更离谱的是,编程、长文本处理、复杂提示等细分赛道上,它直接和Pro版平起平坐,堪称“以下克上”的典范。
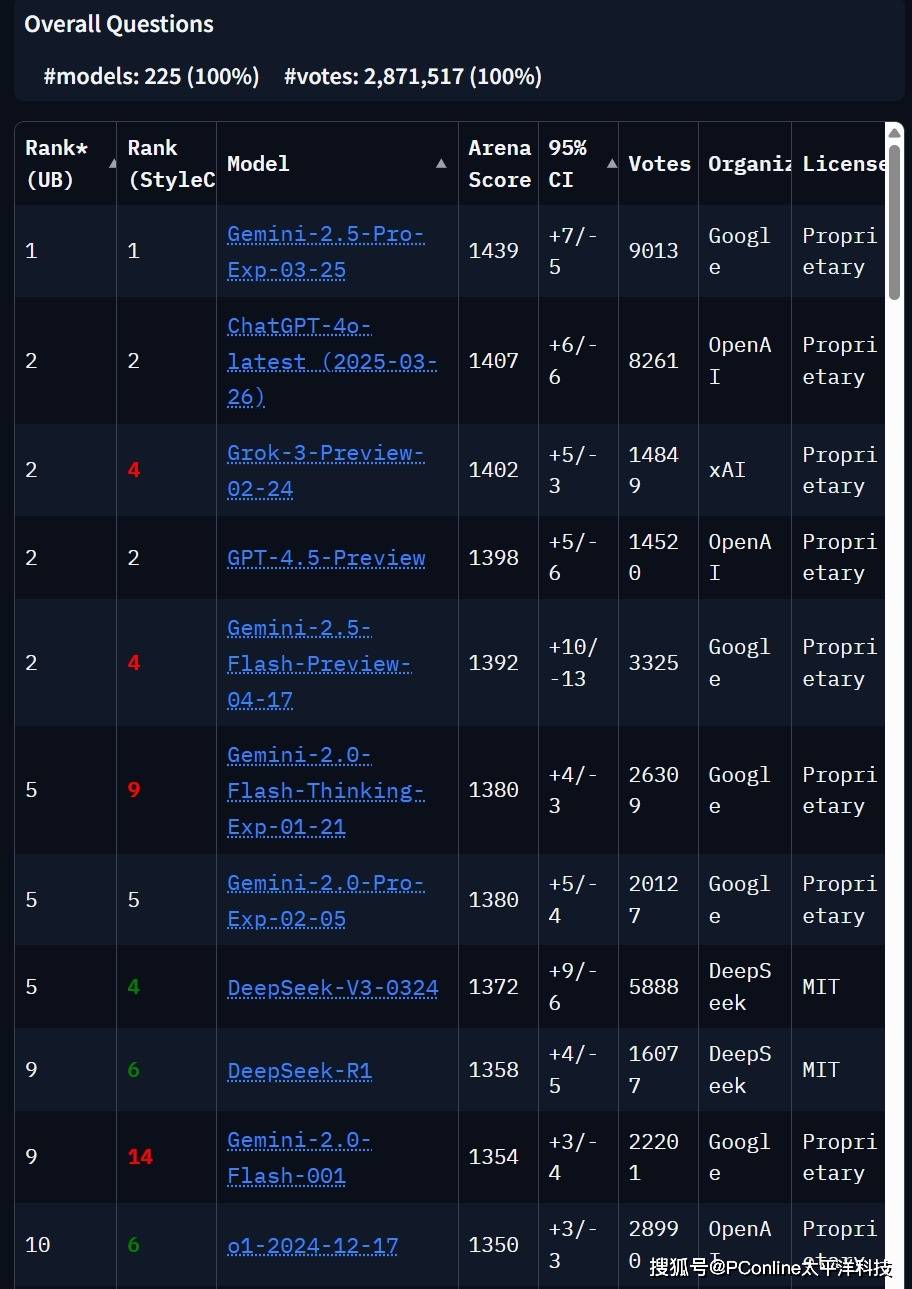
在数学(AIME 2025)、多模态推理(MMMU)、科学问答(GPQA)等硬核测试中,Gemini 2.5 Flash把Anthropic家的Claude 3.7 Sonnet虐到怀疑人生,甚至能和OpenAI最新发布的o4-mini掰手腕。
如果说性能是面子,价格就是里子。在号称“人类最后一次考试”的测试中,它拿下12.1%的成绩,虽然输给o4-mini(14.3%),但价格只有对方的零头啊!
Gemini 2.5 Flash直接把AI推理成本打骨折,输入价格为0.15美元/百万token,输出价格为0.6美元(关闭推理)或3.5美元(开启推理),对比OpenAI的o4-mini(输出4.4美元),直接便宜近6倍!就连以性价比著称的DeepSeek R1(2.19美元)也被按在地上摩擦。
如果按输入输出3:1的比例计算,Gemini 2.5 Flash在同等性能下成本最低,堪称“价格屠夫”。

这逼得OpenAI连夜改价,宣布推出“灵活计费套餐”:处理优先级降级、响应速度变龟、服务器间歇性装死,但价格好歹砍半。
表面上看o4-mini输出价格终于能和谷歌掰手腕,但科技圈老司机们早已看穿真相:没有自家云业务的OpenAI,租着微软Azure服务器搞价格战,相当于用爱发电;反观谷歌,靠着云服务三巨头之一的钞能力,哪怕AI定价再骚也能从别处找补。OpenAI这是用网吧电脑和谷歌超算对轰啊!
能省又能肝,天选牛马AI
Gemini 2.5 Flash的特性在于它把“智能抠门”玩成了技术革命,其动态推理资源管理系统,让AI学会“看人下菜碟”,力求消耗最少tokens,给开发者省钱,像极了给老板省预算的牛马。
此外,开发者可自定义0-24576 token的“脑力配额”,实现从“秒答模式”到“深度思考模式”的无缝切换。
同时,Gemini 2.5 Flash内置的复杂度感知算法,构成其自适应推理机制,能让模型自动判断该“躺平”还是“卷起来”,在Gemini App和网页端中已经可以体验到这一特性。

像翻译谢谢成法语这种极简任务,模型直接调用预训练知识库,响应速度堪比人类反射弧。同样的问题丢给DeepSeek R1,还得思考8秒呢。

而像计算悬臂梁的最大弯曲应力这类复杂推理任务,模型会像学霸解压轴题一样拆解任务,先分解载荷分布、弯矩方程,再调用材料力学公式推导结果,完整度碾压传统模型。
此外,其多模态推理引擎基于Transformer架构升级的混合模态处理单元,支持文本、代码、图像的多维度交叉推理。在开发者实测中,仅凭描述,模型即可生成《创:战纪》风格的HTML游戏代码,甚至自动处理光影渲染逻辑。
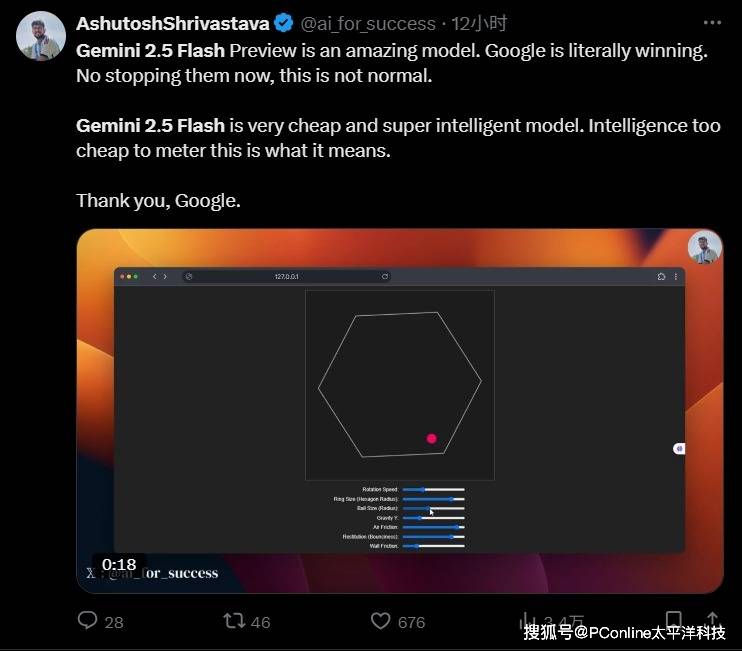
还有人让它模拟物理实验,小球在多边形里精准运动,表现也非常出色,而且很省钱。
值得一提的是,Gemini 2.5 Flash还有模型压缩黑科技,通过量化+剪枝技术,将计算能耗压缩至竞品的1/3,却保持90%以上的性能保留率。通过动态token分配策略,它长文本处理时自动跳过冗余信息,百万token上下文吞吐延迟仅增加12%。并且支持多智能体协同时,资源调度效率提升40%,适合自动化运维、分布式代码生成等企业级场景。
大模型的降本增效时代
Gemini 2.5 Flash的横空出世,本质上是一场“技术平权运动”——当谷歌用云服务巨头的成本优势,把推理价格砍到“白菜价”,AI赛道彻底进入 “既要暴打同行,又要掏空钱包” 的魔鬼竞争模式。

反观谷歌,左手云业务输血,右手AI模型打劫,硬生生把大模型玩成了“互联网思维”——羊毛出在狗身上,猪来买单。
这场战役的终极启示或许是:未来的AI竞争,早已不是单纯拼参数、刷榜单的“学霸内卷”,而是 云服务、算法、商业模式的“三位一体”大乱斗。当大厂们集体开启“降本增效”狂暴模式,开发者终于能喊出那句:“感谢谷歌老铁,让咱用奶茶钱雇了个AI学霸!”
最后灵魂一问:当推理成本被卷到趋近于零,下一个被AI颠覆的,会不会是……你的工资?(手动狗头)
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






